Abstract: On this page, we showcase the generative capabilities of InteractAvatar. All videos presented here were generated by our model and include corresponding audio. The content is organized into eight sections, demonstrating capabilities ranging from multi-object scenarios to fine-grained multi-step controls.
Recommended: Click the sound icon on videos for the full audio-visual experience.
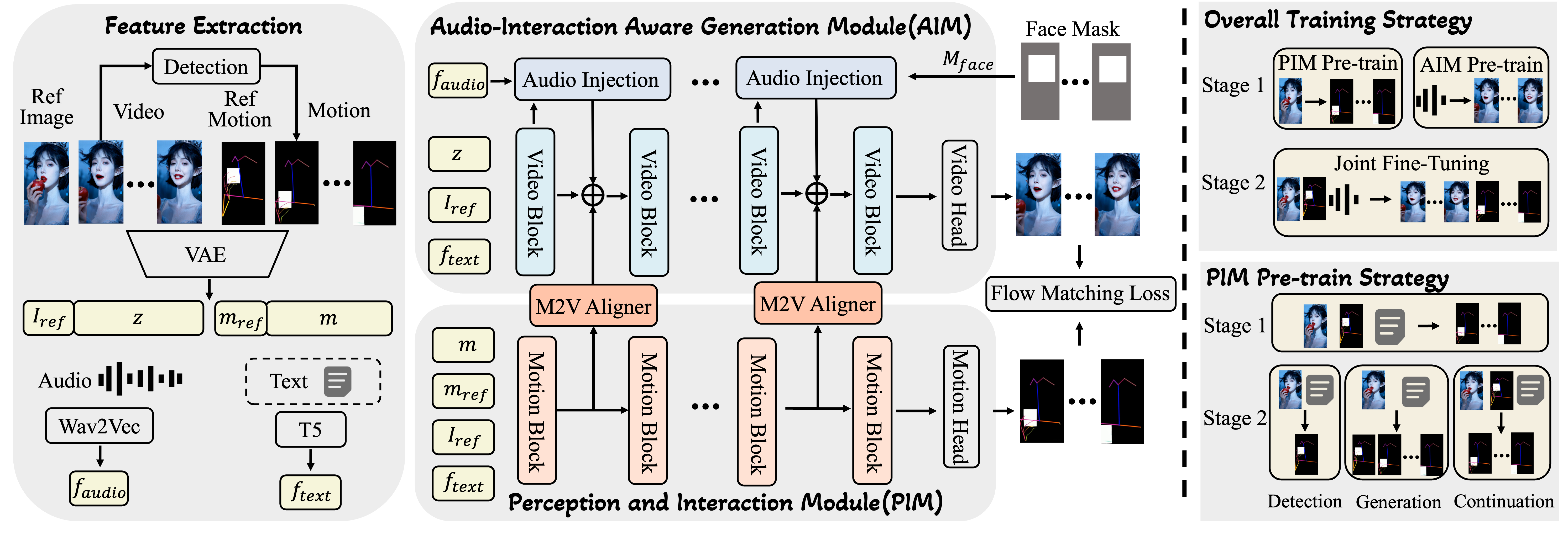
Method
We propose InteractAvatar, a novel dual-stream DiT generation model centered on Grounded Human-Object Interaction for Talking Avatars, which explicitly decouples perception planning from video synthesis. Beyond the core capability of GHOI, our method is a unified framework with flexible multimodal control, accepting any combination of text, audio, and motion as inputs.
Multi-object Scenario
In this section, all videos begin from a non-interactive reference frame containing multiple objects . The model must interpret the text command to determine which object to interact with and how to do so, inferring the object's location and properties directly from the image. InteractAvatar successfully generates realistic videos from a static starting point while maintaining high audio-visual consistency.
❮
Pick up the apple from the table with one hand, then place it back on the table.
Pick up the headphones on the table with both hands and put them on your ears.
Reaching out and pick up the phone on the table, then began to check the messages.
Use one hand to pick up the camera on the table, hold the camera with both hands...
Take your hand off your head and hold the doll on the table with one hand.
First extends one hand towards a plush toy, then gently touches it with your fingers.
Pick up the basketball on the table with both hands, hold it steadily against your chest.
One hand picked up the cup on the table, and with both hands held the cup to take a sip
❯
Multi Step Interaction
We demonstrate more complex scenarios where text prompts involve fine-grained multi-step control. InteractAvatar successfully adheres to these detailed sequential instructions, showcasing its strong command-following capabilities.
First, gently touch the flower in front of you. Then, extend one hand to pick up the hat on the table.
First, extend both hands and pick up the bag on the table. Then, stand up and hold the bag up in front of your chest.
First, carry the bag and walk forward. Then, raise the bag and hold it in front of your chest for display.
First, extend one hand to hold the vase, then lift the vase and show it towards the window.
Multi-Action Generation
Here, we demonstrate the ability to follow commands containing multiple sequential actions. The model accurately executes each action in the correct temporal order, demonstrating a robust understanding of complex, time-ordered instructions.
❮
First, raise one hand to greet, then make a heart shape with both hands.
First, make the victory gesture with both hands, then clench your fists and cheer on!
First, cross your arms over your chest. Then, make a heart shape with your hands.
First, make the OK gesture with both hands, and then give a thumbs-up with one hand.
First, put one hand to your mouth and speak. Then, raise both hands to greet.
First, make the OK gesture with one hand, and then change it to the thumbs-up gesture.
First, cross your arms over your chest. Then, make a heart shape with your hands.
First, cross your arms over your chest. Then start clapping.
❯
Long Video Generation and Chinese
We demonstrate the long video generation and chinese language ability of our InteractAvatar. We divided the long video into several segments, with each segment having its own independent action description. InteractAvatar successfully adheres to these segmented sequential instructions and maintains the temporal coherence and ID consistency in long videos, showcasing its strong long video generation capabilities.
❮
0-4s, Touch the apple with your hand.
12-16s, Move the apple on the table forward.
16-20s, Picks up the apple with one hand.
0-4s, Show the cooking pot forward.
16-22s, Hold the pot with both hands and walk forward.
8-12s, Pick up the can and examine it in front of you.
0-4s, Touch the camera with one hand.
12-16s, Pick up the camera with both hands.
12-16s, Lift the cup to your chest with both hands.
0-4s, Holding the ball in hand and putting it down.
4-8s, Raise the ball with your hand.
4-8s, Hold the doll tightly.
❯
Song-Driven Generation
We demonstrate the song-driven generation ability of our InteractAvatar, with segmented action description. InteractAvatar generates high-quality lip dynamics and co-speech gestures in challenging singing scenarios, accurately following the action command.
❮
0-4s, Give a thumbs-up with one hand.
0-4s, Make the OK gesture with one hand.
12-16s, Clap with both your hands.
12-16s, Make the victory gesture with both hands.
0-4s, Make a heart shape with both hands.
8-12s, Put you palms together.
12-16s, Clench your fists and cheer on.
0-4s, Clench your fists and cheer on.
20-24s, One hand resting on your chin.
0-4s, Clench your fists and cheer on.
8-12s, Touch your hair with one hand.
20-24s, Make the OK gesture.
0-4s, Raise both hand to greet.
0-4s, Raise both hand to greet.
20-24s, Give a thumbs-up with one hand.
0-4s, Make the OK gesture with one hand.
0-4s, Covering the face with both hands.
12-16s, Cross your arms over your chest.
20-24s, Give a thumbs-up with one hand.
Static
Static
❯
SOTA Comparison
We compare our method with current SOTA models. Our method demonstrates powerful text-aligned human-object interaction generation, while greatly preserving the audio-driven performance. Current SOTA audio-driven methods tend to generate only lip dynamics but ignore interaction instructions.
❮
One hand lifts the bag on the stool to the chest, while the other hand supports the bottom of the bag.
Reference
Ours
HY-Avatar
HuMo
Fantasy
Wan-S2V
OminiAvatar
First gently holds the stem of the rose with one hand, then strokes the petals of the rose with the index and middle fingers of other hand.
Reference
Ours
HY-Avatar
HuMo
Fantasy
Wan-S2V
OminiAvatar
Holding a brush in right hand, with the bristles facing towards face, gently touching the cheek as you applies makeup to face.
Reference
Ours
HY-Avatar
HuMo
Fantasy
Wan-S2V
OminiAvatar
First extend both hands to hold the vase, and then move it forward.
Reference
Ours
HY-Avatar
HuMo
Fantasy
Wan-S2V
OminiAvatar
❯
Interaction with Different Objects
This section showcases interactions with 32 different types of common, everyday objects. InteractAvatar exhibits stable and consistent performance across all object categories, demonstrating the model's strong robustness and generalization.
❮
One hand holds the T-shirt, while the other hand is stroking it and giving an introduction.
Pulling the suitcase with one hand and walking forward.
Crouch down and then lowered the cardboard box from your chest onto the ground, ensuring it landed smoothly.
Hold the red wine bottle with both hands, picks it up from the table, and slowly moves it towards yourself while keeping eyes on the bottle.
Place the cooking pot with both hands on the kitchen counter.
Pick up the milk on the table and introduce it, then turn around
Pick up the plate from the table and turn around
Picks up the iPad from the nightstand and places it on the bed.
Crossing both hands to clutch the plush toy and hugging it more tightly.
Holds a fan in one hand, directs the fan towards face, shake your wrist to form a fanning motion.
Steadily lifted the basketball from your chest with both hands, then slowly moved it forward until it was securely placed in the center of the wooden table.
First placed one hand on the flute, then slowly raised other hand to pick up the flute.
Gently lifted the sunglasses with right hand and let them slide down from above eyes.
Puts the headphones with both hands on your head, and then adjusts them to ensure comfort.
Gently strokes the leaves of the potted plant with right hand while holding the pot steady with left hand
Gently strokes the top edge of the backpack with both hands then strokes one hand on the bottom edge of the backpack
Raise hat with both hands and put the hat in your hand on your head.
Reach out both hands to hold the wooden cup placed on the table, with your right index finger touch the edge.
Supporting the sound box with both hands, and begin to introduce.
While speaking, applying lipstick to the lower lip.
One hand holds the top of the Lego toy, the other hand supports the bottom, and gently lifts it.
Extends one hand towards the rice cooker, gently touching the edge of the lid, preparing to lift it.
Raise the camera with both hands and look at the camera screen in front of you.
Holding the shoe with one hand and pointing at it with other hand, then display it.
❯
Single Action Results
This section illustrates the model's ability to naturally extrapolate from object interaction to human action control. InteractAvatar can precisely control body movements based on text commands.
❮
Wave one hand to greet.
Raise one hand and make a victory gesture.
Squat down.
Put both hands on your hips.
Wave one hand to greet.
Raise both hands in front of you and then wave them to greet.
Raise one hand and give a thumbs-up forward.
Raise one hand and make the OK gesture.
❯
Audio-driven Results
This section showcases InteractAvatar's performance in a instruction-free, audio-only setting. This demonstrates that beyond interaction and action control, our model retains the core capabilities of generating high-quality lip dynamics and co-speech gestures.
❮
❯
Motion-driven Results
This section highlights InteractAvatar's responsiveness to explicit motion signals. As a unified digital human model, it can be controlled by any combination of text, audio, and motion.